
Wersja 2.2 pakietu Hortonworks Data Platform (HDP) zawiera tysiące małych poprawek oraz nowych funkcjonalności, począwszy od dostępu do danych przez bezpieczeństwo środowiska aż po warstwę zarządzania oraz systemu uaktualnień. Z każdą wersją staje się on łatwiejszy do wdrożenia w przedsiębiorstwie jako kluczowy element nowoczesnej architektury danych (Modern Data Architecture).
Wewnątrz pakietu znajdziemy najnowsze innowacje ze stajni Apache Software Foundation, przygotowującej cały ekosystem wogół Apache Hadoop.
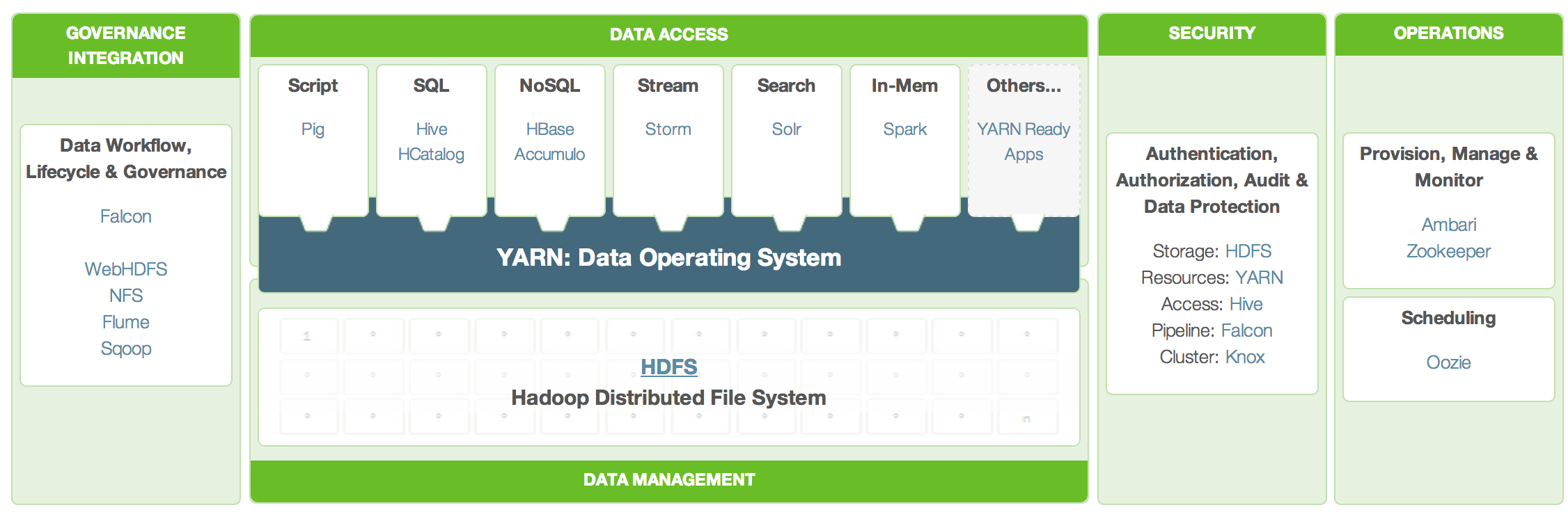
Poniżej zamieściłem schemat podziału architektury i aplikacji rozwiązania HDP pomiędzy takie warstwy jak:
Zarządzanie i integracja
- Apache Falcon – Data management and processing platform
- Hadoop WebHDFS – WebHDFS REST API
- HDFS NFS Gateway – Hadoop HDFS NFS Gateway
- Apache Flume – Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data
- Apache Sqoop – Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases
Dostęp do danych
- Apache Pig – Scripting
- Apache Hive – SQL
- Apache HCatalog – SQL
- Apache HBase – NoSQL
- Apache Accumulo – NoSQL
- Apache Storm – Streaming, Realtime Proecssing
- Apache Lucene/Solr – Search
- Apache Spark – In-Memory processing
- YARN Ready – YARN ready apps
Zarządzanie danymi
- Hadoop HDFS – HDFS
Bezpieczeństwo (autentykacja, autoryzacja, audyt i ochrona danych)
- Storage – Hadoop HDFS
- Resources – Hadoop YARN
- Access – Apache Hive
- Pipeline – Apache Falcon
- Cluster – Apache Knox
Utrzymanie.
- Provision, manage & monitor – Apache Ambari, Apache Zookeeper
- Scheduling – Apache Oozie
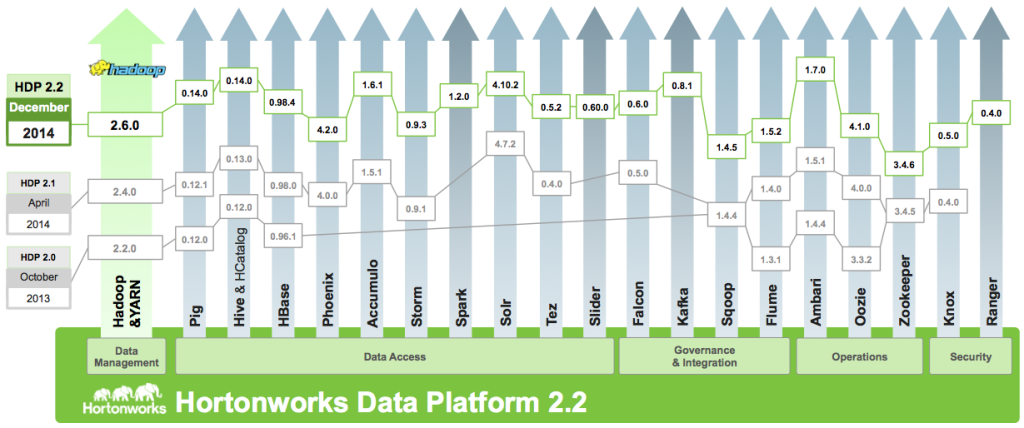
 Poniższa rycina obrazuje ewolucję platformy w przeciągu ostatnich 2 lat z jednoczesnym rozwojem poszczególnych projektów Apache Software Foundation. Wiele firm skupiało się na konkretnych wersjach projektów, tworząc ich własne produkty pochodne, oddalając się od pracy na najnowszych wersjach i utrudniając sobie drogę do aktualizacji. HDP postawiło na możliwie najnowsze oprogramowanie, dając dużą przewagę zarówno technologiczną jak i wydajnościową.
Poniższa rycina obrazuje ewolucję platformy w przeciągu ostatnich 2 lat z jednoczesnym rozwojem poszczególnych projektów Apache Software Foundation. Wiele firm skupiało się na konkretnych wersjach projektów, tworząc ich własne produkty pochodne, oddalając się od pracy na najnowszych wersjach i utrudniając sobie drogę do aktualizacji. HDP postawiło na możliwie najnowsze oprogramowanie, dając dużą przewagę zarówno technologiczną jak i wydajnościową.
YARN w HDP 2.2
Dzięki znacznym zmianom w YARN, otworzyły się nowe możliwości dla silników aplikacji pracujących w ekosystemie Hadoop, traktując go jako efektywne repozytorium danych dostępnych na wiele różnych sposobów. Kolejną ważną zmianą jest umożliwienie uruchamiania zadań o charakterze długiego cyklu życia poprzez zmiany w systemie zarządzania zasobami, wysokiej dostępności, zarządzania zdarzeniami i zabezpieczeń. Użytkownik może dzięki temu wykorzystywać takie zadania podobnie jak zadania charakteryzujące się krótkim cyklem życia. Hortonworks dołączył do społeczności Apache Slider, projektu będącego frameworkiem YARN dla Hadoop, dający możliwość uruchamiania istniejących rozproszonych aplikacji na YARN bez najmniejszych zmian w kodzie, dostarczając jedynie specyfikację w jaki sposób aplikacja powinna zostać uruchomiona.
Od wersji 2.2 YARN może zarządzać zarówno zasobami pamięci RAM jak i procesora, dając większą elastyczność w rozkładaniu obciążenia pomiędzy węzłami klastra oraz lepsze harmonogramowanie.
Enterprise SQL w Hadoop
O ile YARN pozwolił na uruchamianie nowych silników na platformie Hadoop, nadal najbardziej popularnym punktem integracji pozostaje SQL wraz z produktem Apache Hive jako standard. W wydaniu 2.2 udało się wejść w pierwszą fazę inicjatywy Stinger.next, dążącą do poprawy prędkości, skali i składni SQL, stając się w pełni interaktywnym systemem zapytań.

Poprawiła się także wydajność Hive dzięki Cost Based Optimizer, używający statystyk do generowania planów wykonawczych i wybierając najbardziej efektywną ścieżkę w zależności od wymaganych zasobów.
Integracja Spark z YARN
Apache Spark jest atrakcyjnym API ułatwiającym programistom wykorzystywanie danych do szybkich obliczeń, algorytmów uczących się i innych metod. Dzięki możliwości wykorzystania Spark z YARN oraz lepszej integracji z Hive, możliwe jest lepsze wykorzystywanie i dostarczanie danych.
Komunikacja „Internetu Rzeczy” dzięki Kafka
Apache Kafka szybko stał się standardem dla systemów powiadomień typu publish-subscribe, oferując wielką skalę, odporność na awarie w środowiskach Hadoop. Często wykorzystywany ze Storm i Spark umożliwia strumieniowanie zdarzeń w Hadoop w czasie rzeczywistym, stając się idealnym rozwiązaniem dla idei „Internetu Rzeczy”
Podwyższona dostępność dzięki płynnym aktualizacjom
Nowe wersjonowane paczki oprogramowania wraz z systemem HDFS wysokiej dostępności pozwalają na aktualizowanie modułów oprogramowania i ich restartów bez negatywnego wpływu na działanie całego klastra.
Ulepszenia w warstwie zarządzania i monitoringu Hadoop
Wykorzystanie otwartego Apache Ambari do zarządzania klastrem Hadoop pozwoliło na utworzenie własnych widoków wewnątrz Ambari Views Framework na zasadzie wtyczek do interfejsu użytkownika, własnej wizualizacji danych oraz przeniesienie do konsoli Web. Dostawcy oprogramowania otrzymali możliwość tworzenia kontenerów z aplikacjami które mogą rozszerzać możliwości, bezpieczeństwo, łatwość zarządzania. Ambari Blueprints dodało funkcjonalność tworzenia szablonów klastrów, zawierających wybrany stos aplikacji (w tym wypadku odpowiednią wersję HDP), układ komponentów oraz ich konfiguracji umożliwiając powoływanie instancji klastra Hadoop przy pomocy REST API. Rozszerzanie stosów aplikacji pozwala na dodawanie własnych komponentów oraz zarządzanie ich konfiguracją.
Automatyczne kopie zapasowe do Microsoft Azure i Amazon S3
Architekci danych nadal muszą podchodzić do Hadoop jak do innego systemu w centrum danych, zapewniając ciągłość biznesową dzięki wykorzystaniu replikacji zarówno w obrębie swoich fizycznych środowisk jak i replikacji do środowisk Cloud Computing. W HDP 2.2 dodana została zdolność Apache Falcon do tworzenia automatycznych polityk wykonywania kopii zapasowych do Chmury Amazon S3 oraz Microsoft Azure.
Poniżej znajdują się szczegółowe informacje o wersjach oprogramowania Apache:
| Wersja | Wersja |
|---|---|
| Apache Hadoop 2.6.0 | Apache Accumulo 1.6.1 |
| Apache Ranger 0.4.0 | Apache DataFu 1.2.0 |
| Apache Flume 1.5.2 | Apache HBase 0.98.4 |
| Apache Hive 0.14.0 | Hue 2.6.1 |
| Apache Kafka 0.8.1.1 | Apache Knox 0.5.0 |
| Apache Mahout 0.9.0 | Apache Oozie 4.1.0 |
| Apache Pig 0.14.0 | Apache Phoenix 4.2.0 |
| Apache Sqoop 1.4.5 | Apache Slider 0.60.0 |
| Apache Tez 0.5.2 | Apache Storm 0.9.3 |
| Apache Falcon 0.6.0 | Apache Zookeeper 3.4.6 |
Tech Previews in This Release
- HDFS Encryption
- HDFS read/write storage tier
- HDFS-6932 HDFS Blocking Mover/Balancer from moving files/blocks to/from transient storage.
- Falcon Data Lineage
- Falcon Graph View of Dependencies
- Phoenix support for local secondary indexes
- YARN support for Docker
What’s New in this Release (Nowości HDP 2.2)
HDP 2.2 includes the following new features:
-
Accumulo
- Accumulo multi-datacenter replication
- Accumulo on YARN via Slider
-
Falcon
- Authorization
- Lineage Enhancement
- HCat Replication and Retention
- Archive to Cloud
-
Flume
- Flume streaming to Hive for secure and unsecure clusters
-
HBase
- HBase HA: Timeline-consistent replicas with realtime replication
- HBase block cache compression
- HBase on YARN via Slider
-
HDFS
- Heterogenous Storage: Support for SSD Tier
- Heterogenous Storage: Support for Archival Tier
- Operating secure DataNode without requiring root access
- AES support for faster wire encryption
-
Hive
- Support for SQL Transactions with ACID semantics
- Support for SQL Temporary Tables
- Better optimize queries using Cost Based Optimizer
- Add performance improvements for various queries
- Security additions such as Grant, Revoke with a choice of using Native Security or Ranger security with both integrated completely in Hive
-
Knox
- Support for HDFS HA
- Installation and configuration with Apache Ambari
- Service-level authorization with Apache Ranger
- YARN REST API access
-
Oozie
- Oozie HA on secure clusters
-
Phoenix
- Subquery support
- Robust secondary indexes
- Build secondary index during bulk import
-
Pig
- Pig on Tez
- Including DataFu for use with Pig
-
Ranger
- Storm Authorization and Auditing
- Knox Authorization and Auditing
- Deeper integration with HDP stack: Hive Auth API support for grant/revoke commands, grant/revoke commands in HBase, and Windows support
- REST API’s for policy manager, local audit log storage in HDFS, and support for Oracle DB for policy store and audits
-
Sqoop
- Support for all Hive types via HCatalog import/export
- Support for multiple partition keys
- Integration with Hadoop Credential Management Framework
-
Storm
- Storm clusters can now be provisioned via Ambari
- Storm can now run on YARN based clusters using Apache Slider
- Storm now supports kerberos based authentication and pluggable authorization
- Pre-built Spouts for JMS, HBase lookups and Bolts for Kafka, Hive.
- Real-time visualization of running topologies and its associated metrics
- REST APIs for topology stats
-
Tez
- Tez Debug Tooling & UI
-
YARN
- Support long running services: handling of logs, containers not killed when AM dies, secure token renewal, YARN Labels for tagging nodes for specific workloads
- Support for CPU Scheduling and CPU Resource Isolation through CGroups
- Work-preserving restarts of ResourceManager and NodeManager
- Support node labels during scheduling
- Global, shared cache for application artifacts
- REST API for YARN application submission and termination
- Application Timeline Server is supported in a Secure (Kerberized) cluster